Do not try and bend the spoon. That's impossible. Instead... only try to realize the truth.
Do not try and bend the spoon.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Do not try and bend the spoon.
It’s the question that drives us!
This is a page not in the main menu
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Short description of portfolio item number 1
Short description of portfolio item number 2
Published in SIGGRAPH '16, 2016
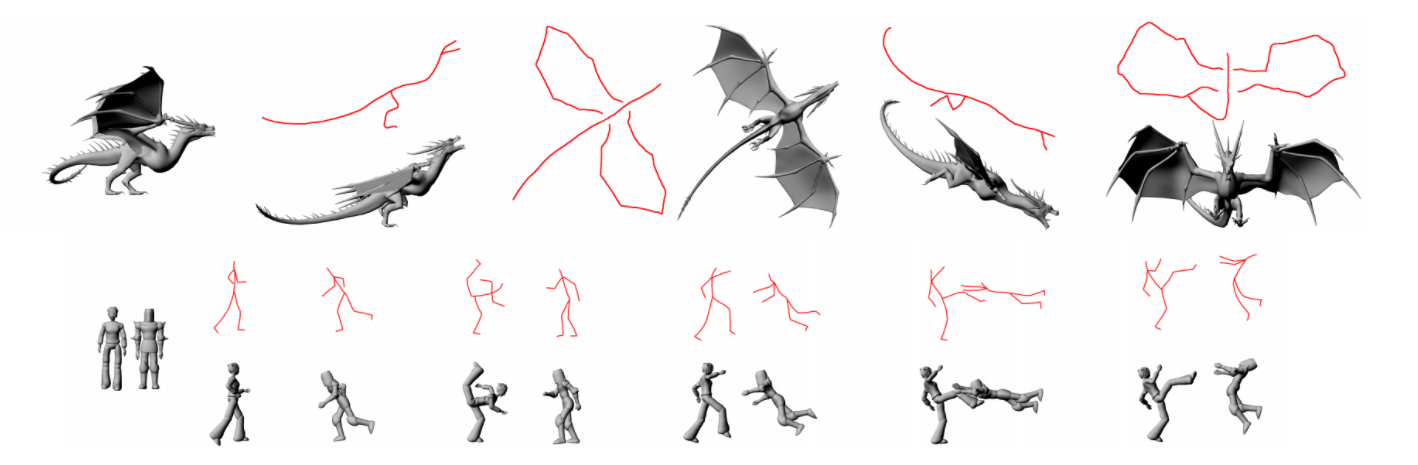
Sketch as the most intuitive and powerful 2D design method has been used by artists for decades. However it is not fully integrated into current 3D animation pipeline as the difficulties of interpreting 2D line drawing into 3D. Several successful research for character posing from sketch has been presented in the past few years, such as the Line of Action [Guay et al. 2013] and Sketch Abstractions [Hahn et al. 2015]. However both of the methods require animators to manually give some initial setup to solve the corresponding problems. In this paper, we propose a new sketch based character posing system which is more flexible and efficient. It requires less input from the user than the system from [Hahn et al. 2015]. The character can be easily posed no matter the sketch represents a skeleton structure or shape contours.
Recommended citation: Barbieri, Simone, et al. "Enhancing character posing by a sketch-based interaction." ACM SIGGRAPH 2016 Posters. ACM, 2016. https://dl.acm.org/doi/10.1145/2945078.2945134
Published in ForItAAL2019, 2019
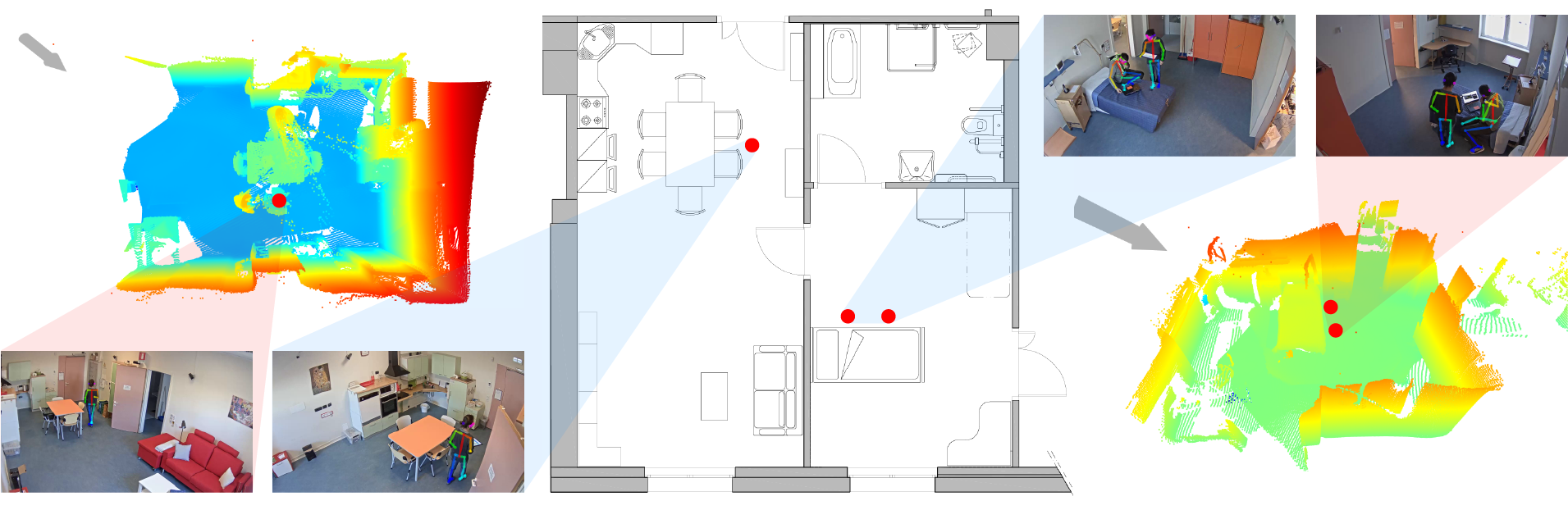
Living labs are spaces where public and private stakeholders work together to develop and prototype new products, technologies and services in real environments embedded in the community or market place. This paper outlines the approach chosen by AUSILIA (Assisted Unit for Simulating Independent Living Activities), a living lab established in Provincia Autonoma di Trento in 2016 to develop an innovation model for taking care of the elderly or disabled patient by fusion of technology innovation and patient centered integrated care approach. AUSILIA goal is triple: i. to provide an innovative framework based on augmented virtual reality for occupational therapy in ageing and fragile individuals; ii. to help people who are losing autonomy and independence living at home reducing care burden; iii. warrant continuous innovation through the mixed contribution of the academy and private enterprise. The paper describes the specific solutions adopted for the three objectives, reporting an implementation example for each of them.
Recommended citation: Grisenti, Andrea, et al. "Technological Infrastructure supports new paradigm of care for healthy aging: The Living Lab Ausilia." 10 Forum Italiano Ambient Assisted Living, 19-21 Giugno 2019, Ancona, Italia http://mmlabsites.disi.unitn.it/ausilia/index.php/pubblicazioni/
Published in ICIAP 2019, 2019
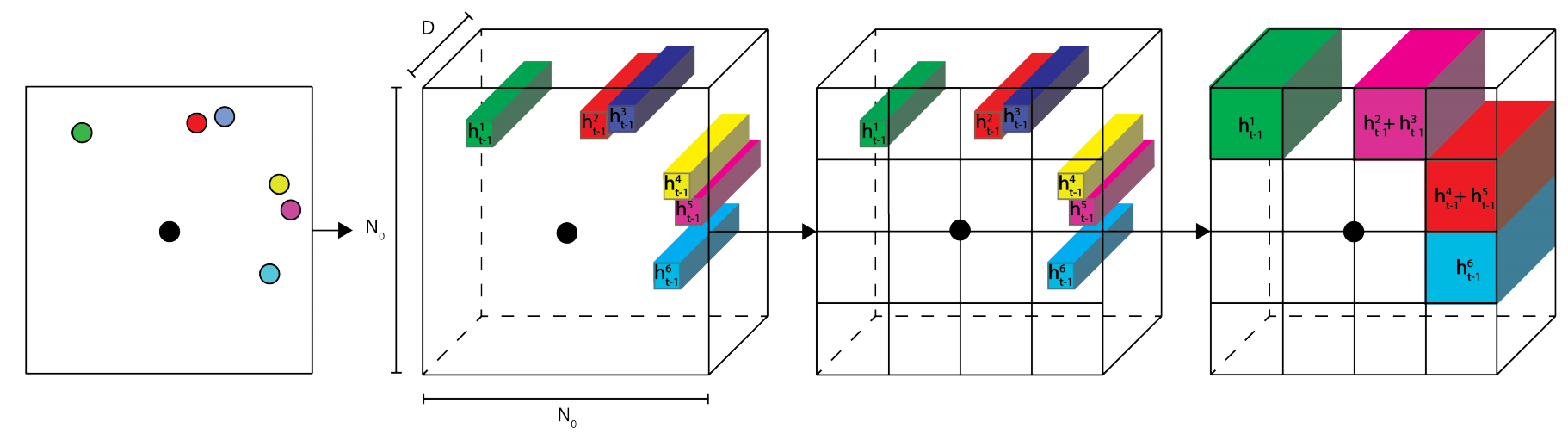
Social modeling of pedestrian dynamics is a key element to understand the behavior of crowded scenes. Existing crowd models like the Social Force Model and the Reciprocal Velocity Obstacle, traditionally rely on empirically-defined functions to characterize the dynamics of a crowd. On the other hand, frameworks based on deep learning, like the Social LSTM and the Social GAN, have proven their ability to predict pedestrians trajectories without requiring a predefined mathematical model. In this paper we propose a new paradigm for crowd simulation based on a pool of LSTM networks. Each pedestrian is able to move independently and interact with the surrounding environment, given a starting point and a destination goal.
Recommended citation: Bisagno, Niccolo, et al. "Virtual Crowds: An LSTM-Based Framework for Crowd Simulation." International Conference on Image Analysis and Processing. Springer, Cham, 2019. https://link.springer.com/chapter/10.1007/978-3-030-30642-7_11
Published in ICDSC 2019, 2019
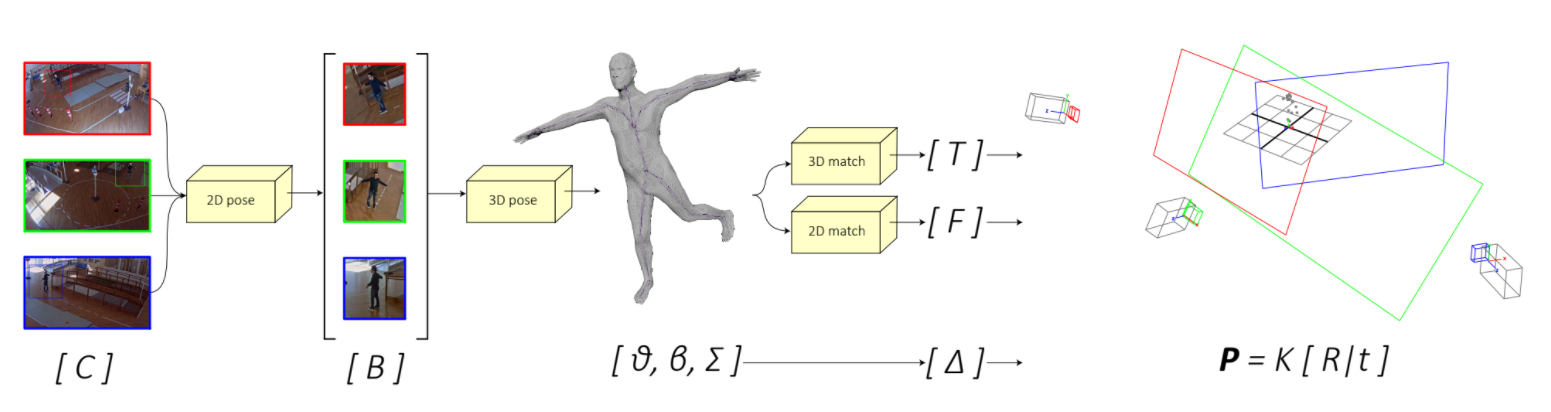
Camera resectioning is essential in computer vision and 3D reconstruction to estimate the position of matching pinhole cameras in 3D worlds. While the internal camera parameters are usually known or can be easily computed offline, in camera networks extrinsic parameters need to be computed each time a camera changes position, thus not allowing for smooth and dynamic network reconfiguration. In this work we propose a fully markerless, unsupervised, and automatic tool for the estimation of the extrinsic parameters of a camera network, based on 3D human mesh recovery from RGB videos. We show how it is possible to retrieve, from monocular images and with just a weak prior knowledge of the intrinsic parameters, the real-world position of the cameras in the network, together with the floor plane. Our solution also works with a single RGB camera and allows the user to dynamically add, re-position, or remove cameras from the network.
Recommended citation: Garau, Nicola, and Nicola Conci. "Unsupervised continuous camera network pose estimation through human mesh recovery." Proceedings of the 13th International Conference on Distributed Smart Cameras. ACM, 2019. https://dl.acm.org/doi/10.1145/3349801.3349803
Published in ICCV 2019, 2019
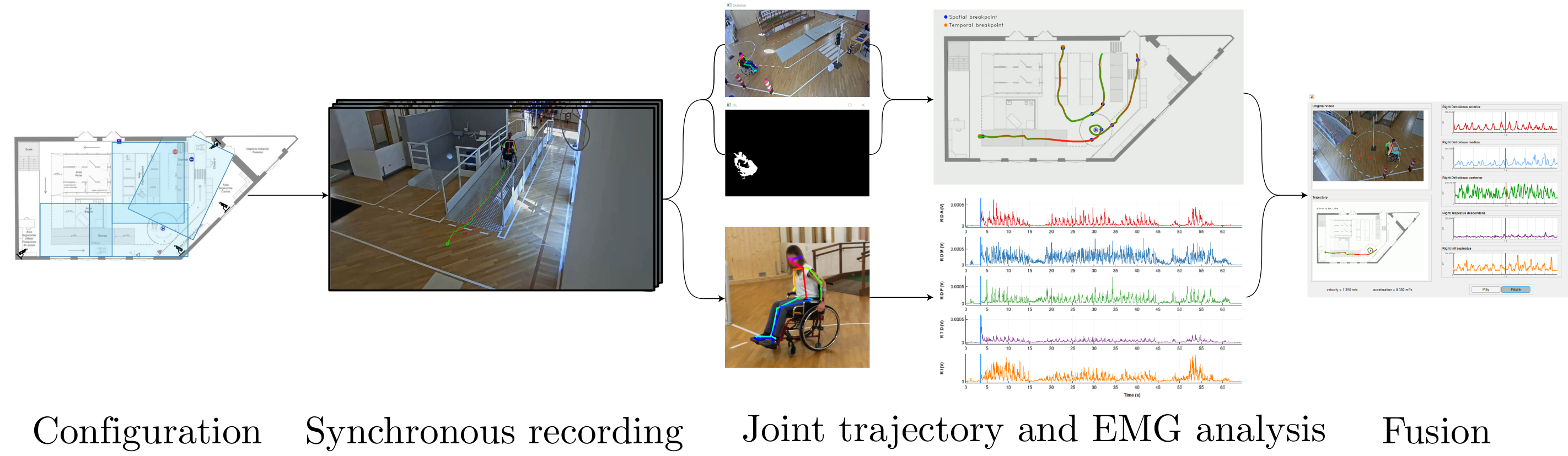
A successful rehabilitation process always requires both medical and infrastructural support. In this paper we focus on paraplegic wheelchair users, aiming at understanding the correlation between accuracy in guidance and muscular fatigue, while moving on a known training path. In particular, we study the trajectories performed and the corresponding shoulder forces distribution, while changing the inclination of the seat. At the motor level, the point of interest is the shoulder, as, in the prolonged use of wheelchairs with manual self-propulsion, it is generally source of pain. The objective is to demonstrate that there is a potential relationship between trajectory discontinuities and shoulder pain, and foster the development of best practices aimed at preventing the raise of shoulder-related pathologies, by correcting the user's movements and the wheelchair setup. This project is meant to be a first study of the subject, so far little addressed, and is not meant to be a clinical study. The experiments have been conducted within the premises of the Living Lab AUSILIA and validated with the help of experienced medical personnel.
Recommended citation: Sebastiani, Maddalena, et al. "Joint Trajectory and Fatigue Analysis in Wheelchair Users." Proceedings of the IEEE International Conference on Computer Vision Workshops. 2019. https://ieeexplore.ieee.org/document/9022098
Published in RTIP 2020, 2020
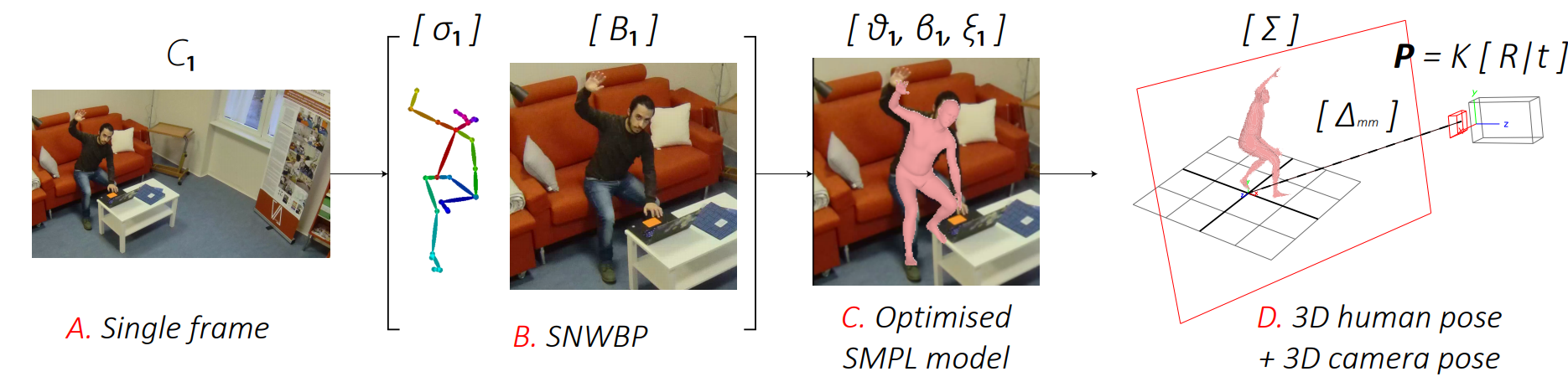
Camera calibration is a necessary preliminary step in computer vision for the estimation of the position of objects in the 3D world. Despite the intrinsic camera parameters can be easily computed ofine, extrinsic parameters need to be computed each time a camera changes its position, thus not allowing for fast and dynamic network re-confguration. In this paper we present an unsupervised and automatic framework for the estimation of the extrinsic parameters of a camera network, which leverages on optimised 3D human mesh recovery from a single image, and which does not require the use of additional markers. We show how it is possible to retrieve the real-world position of the cameras in the network together with the foor plane, exploiting regular RGB images and with a weak prior knowledge of the internal parameters. Our framework can also work with a single camera and in real-time, allowing the user to add, re-position, or remove cameras from the network in a dynamic fashion.
Recommended citation: Garau, Nicola, Francesco G. B. De Natale and Nicola Conci. "Fast automatic camera network calibration through human mesh recovery" J Real-Time Image Proc 17 (2020). https://link.springer.com/article/10.1007/s11554-020-01002-w
Published in ICIAP 2022, 2021
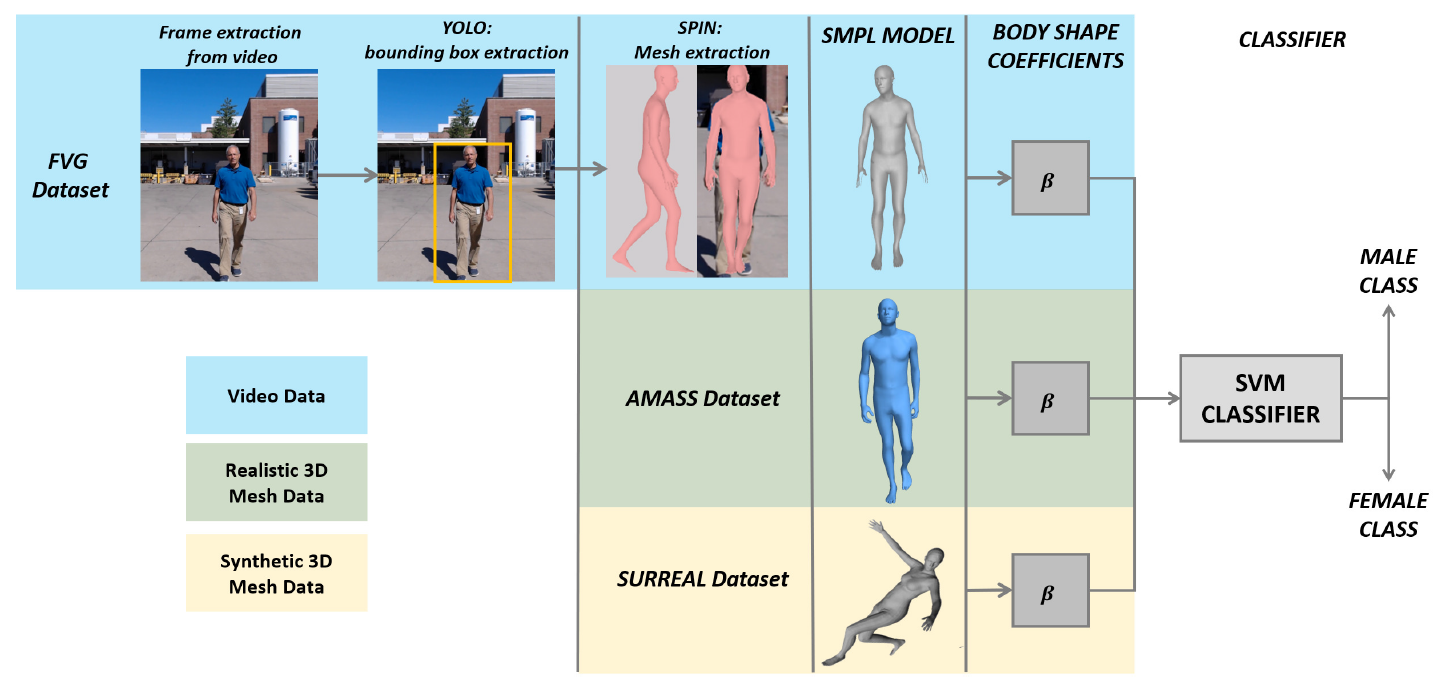
Gender recognition from images is generally approached by extracting the salient visual features of the observed subject, either focusing on the facial appearance or by analyzing the full body. In real-world scenarios, image-based gender recognition approaches tend to fail, providing unreliable results. Face-based methods are compromised by environmental conditions, occlusions (presence of glasses, masks, hair), and poor resolution. Using a full-body perspective leads to other downsides: clothing and hairstyle may not be discriminative enough for classification, and background cluttering could be problematic. We propose a novel approach for body-shape-based gender classification. Our contribution consists in introducing the so-called Skinned Multi-Person Linear model (SMPL) as 3D human mesh. The proposed solution is robust to poor image resolution and the number of features for the classification is limited, making the recognition task computationally affordable, especially in the classification stage, where less complex learning architectures can be easily trained. The obtained information is fed to an SVM classifier, trained and tested using three different datasets, namely (i) FVG, containing videos of walking subjects (ii) AMASS, collected by converting MOCAP data of people performing different activities into realistic 3D human meshes, and (iii) SURREAL, characterized by synthetic human body models. Additionally, we demonstrate that our approach leads to reliable results even when the parametric 3D mesh is extracted from a single image. Considering the lack of benchmarks in this area, we trained and tested the FVG dataset with a pre-trained Resnet50, for comparing our model-based method with an image-based approach.
Recommended citation: Martinelli, Giulia, Nicola Garau, and Nicola Conci. "Gender Recognition from 3D Shape Parameters." International Conference on Image Analysis and Processing. Springer, Cham, 2022. https://link.springer.com/chapter/10.1007/978-3-031-13324-4_18
Published in ICCV 2021 (ORAL), 2021
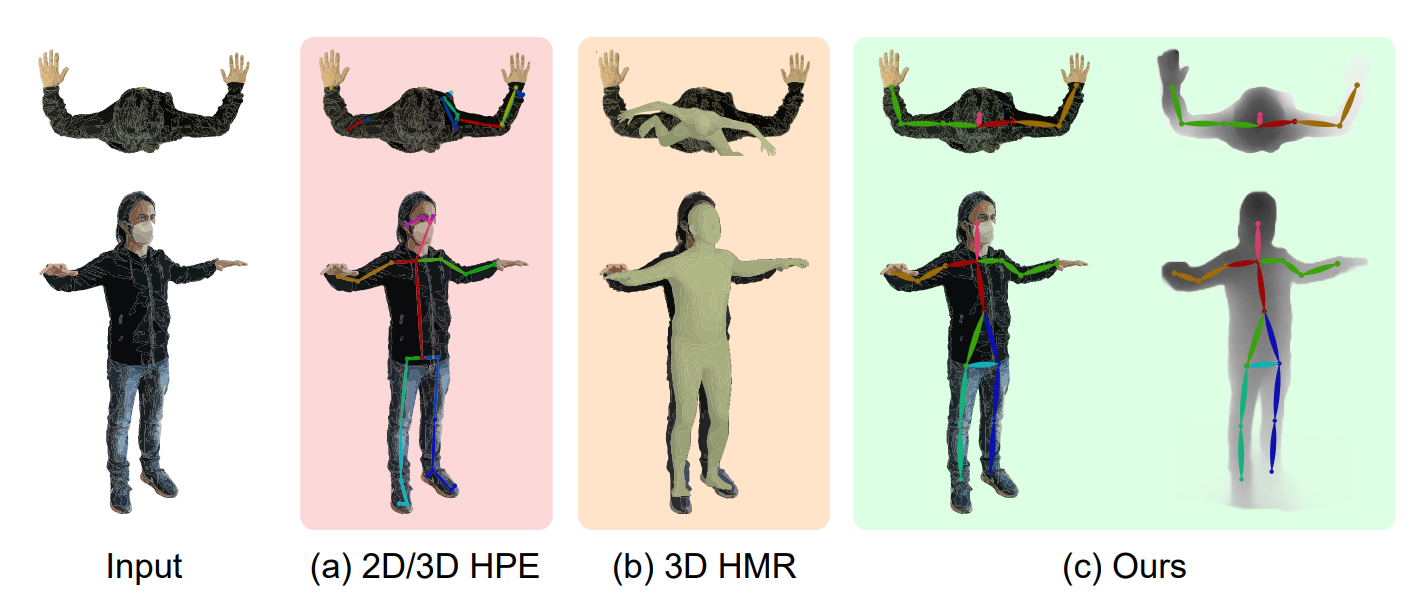
Human Pose Estimation (HPE) aims at retrieving the 3D position of human joints from images or videos. We show that current 3D HPE methods suffer a lack of viewpoint equivariance, namely they tend to fail or perform poorly when dealing with viewpoints unseen at training time. Deep learning methods often rely on either scale-invariant, translation-invariant, or rotation-invariant operations, such as max-pooling. However, the adoption of such procedures does not necessarily improve viewpoint generalization, rather leading to more data-dependent methods. To tackle this issue, we propose a novel capsule autoencoder network with fast Variational Bayes capsule routing, named DECA. By modeling each joint as a capsule entity, combined with the routing algorithm, our approach can preserve the joints' hierarchical and geometrical structure in the feature space, independently from the viewpoint. By achieving viewpoint equivariance, we drastically reduce the network data dependency at training time, resulting in an improved ability to generalize for unseen viewpoints. In the experimental validation, we outperform other methods on depth images from both seen and unseen viewpoints, both top-view, and front-view. In the RGB domain, the same network gives state-of-the-art results on the challenging viewpoint transfer task, also establishing a new framework for top-view HPE.
Recommended citation: Garau, Nicola, et al. "DECA: Deep viewpoint-Equivariant human pose estimation using Capsule Autoencoders." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021. https://openaccess.thecvf.com/content/ICCV2021/papers/Garau_DECA_Deep_Viewpoint-Equivariant_Human_Pose_Estimation_Using_Capsule_Autoencoders_ICCV_2021_paper.pdf
Published in ICCV 2021, 2021
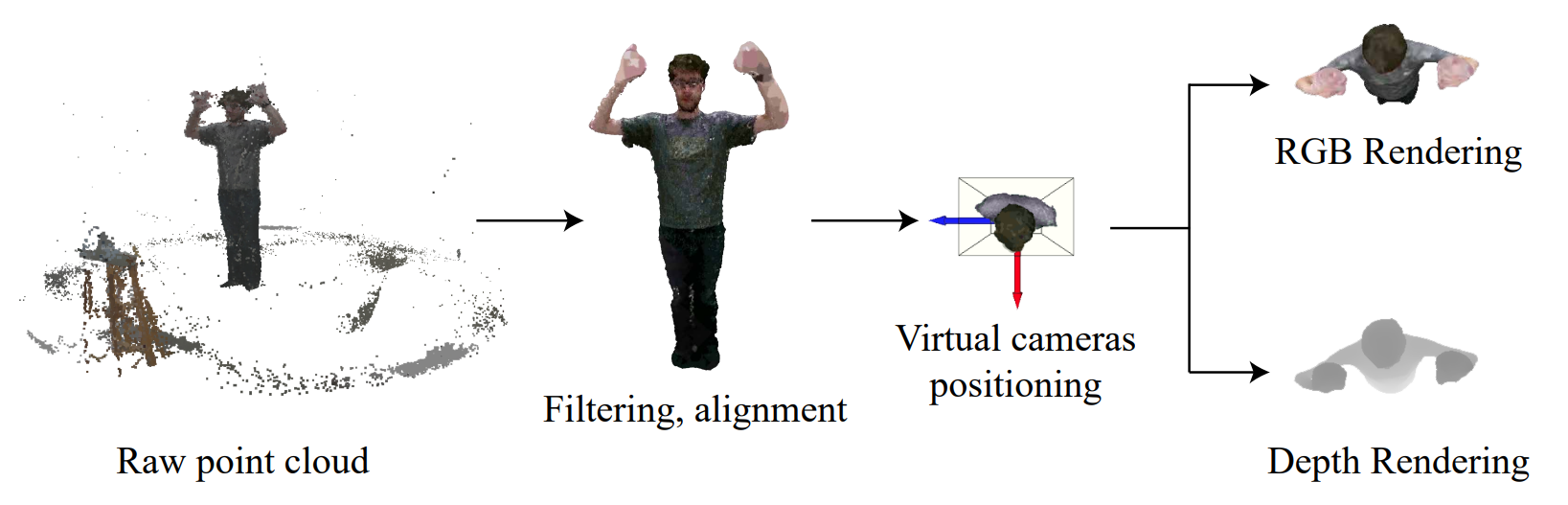
Human pose estimation (HPE) from RGB and depth images has recently experienced a push for viewpoint-invariant and scale-invariant pose retrieval methods. In fact, current methods fail to generalise to unconventional viewpoints due to the lack of viewpoint-invariant data at training time. Existing datasets do not provide multiple-viewpoint observations, and mostly focus on frontal views. In this work, we introduce PanopTOP, a fully automatic framework for the generation of semi-synthetic RGB and depth samples with 2D and 3D ground truth of pedestrian poses from multiple arbitrary viewpoints. Starting from the Panoptic Dataset, we use the PanopTOP framework to generate the PanopTOP31K dataset, consisting of 31K images from 23 different subjects recorded from diverse and challenging viewpoints, also including the top-view. Finally, we provide baseline results and cross-validation tests for our dataset, demonstrating how it is possible to generalise from the semi-synthetic to the real world domain. The dataset and the code will be made publicly available upon acceptance.
Recommended citation: Garau, Nicola, et al. "Panoptop: a framework for generating viewpoint-invariant human pose estimation datasets." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021. https://openaccess.thecvf.com/content/ICCV2021W/DSC/papers/Garau_PanopTOP_A_Framework_for_Generating_Viewpoint-Invariant_Human_Pose_Estimation_Datasets_ICCVW_2021_paper.pdf
Published in CVPR 2022 (ORAL), 2022
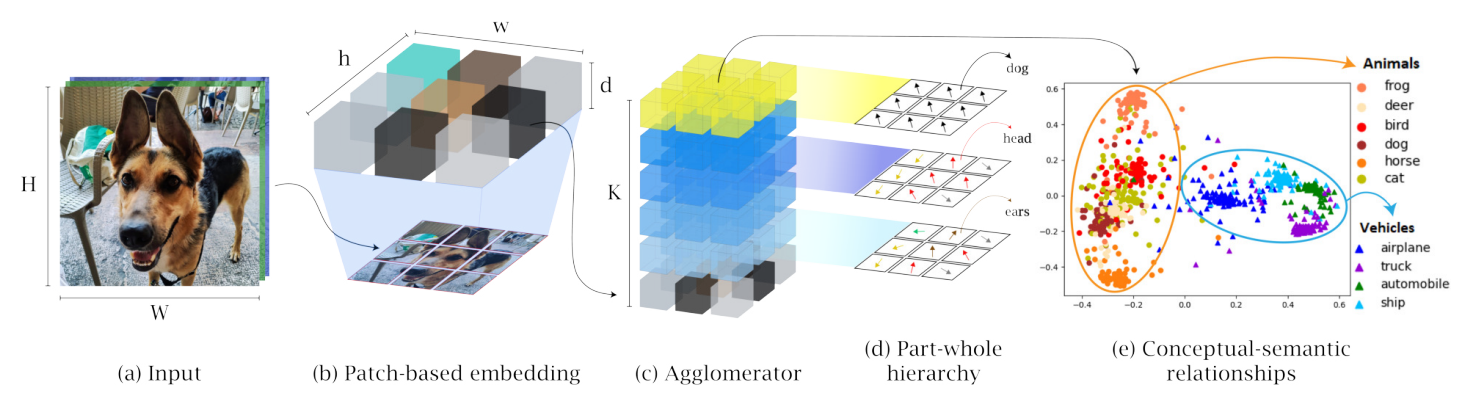
Deep neural networks achieve outstanding results in a large variety of tasks, often outperforming human experts. However, a known limitation of current neural architectures is the poor accessibility to understand and interpret the network response to a given input. This is directly related to the huge number of variables and the associated non-linearities of neural models, which are often used as black boxes. When it comes to critical applications as autonomous driving, security and safety, medicine and health, the lack of interpretability of the network behavior tends to induce skepticism and limited trustworthiness, despite the accurate performance of such systems in the given task. Furthermore, a single metric, such as the classification accuracy, provides a non-exhaustive evaluation of most real-world scenarios. In this paper, we want to make a step forward towards interpretability in neural networks, providing new tools to interpret their behavior. We present Agglomerator, a framework capable of providing a representation of part-whole hierarchies from visual cues and organizing the input distribution matching the conceptual-semantic hierarchical structure between classes. We evaluate our method on common datasets, such as SmallNORB, MNIST, FashionMNIST, CIFAR-10, and CIFAR-100, providing a more interpretable model than other state-of-the-art approaches.
Recommended citation: Garau, Nicola, et al. "Interpretable part-whole hierarchies and conceptual-semantic relationships in neural networks." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. https://openaccess.thecvf.com/content/CVPR2022/papers/Garau_Interpretable_Part-Whole_Hierarchies_and_Conceptual-Semantic_Relationships_in_Neural_Networks_CVPR_2022_paper.pdf
Published in AM 2022 (ORAL), 2022

As of today, the field of networked musical XR is in its infancy. While the next generation networks keep pushing the available bandwidth towards new frontiers, promoting the deployment of new services and applications, a limited amount of residual latency still hinders the possibility for musicians to seamlessly interact over the Internet. In fact, while audiovisual (and audio in particular) streaming has reached high performances, allowing for smooth interaction in many application scenarios such as video calls and dialogues, the study of tools to ensure a flawless immersive interplay experience among musicians is a rather unexplored area. This paper reports a preliminary investigation on a technical setup that couples a networked music performance system with an XR system, conceived to interconnect geographically displaced musicians. The setup we have envisaged has allowed us to identify the existing technical issues in current technologies used for networked musical XR. We discuss such issues and reason about possible future research directions in this area that should be covered to advance the current state of the art.
Recommended citation: Turchet, Luca, Nicola Garau, and Nicola Conci. "Networked Musical XR: where s the limit? A preliminary investigation on the joint use of point clouds and low-latency audio communication." AudioMostly 2022. 2022. 226-230. https://dl.acm.org/doi/abs/10.1145/3561212.3561237
Published in ESAPP 2022, 2022
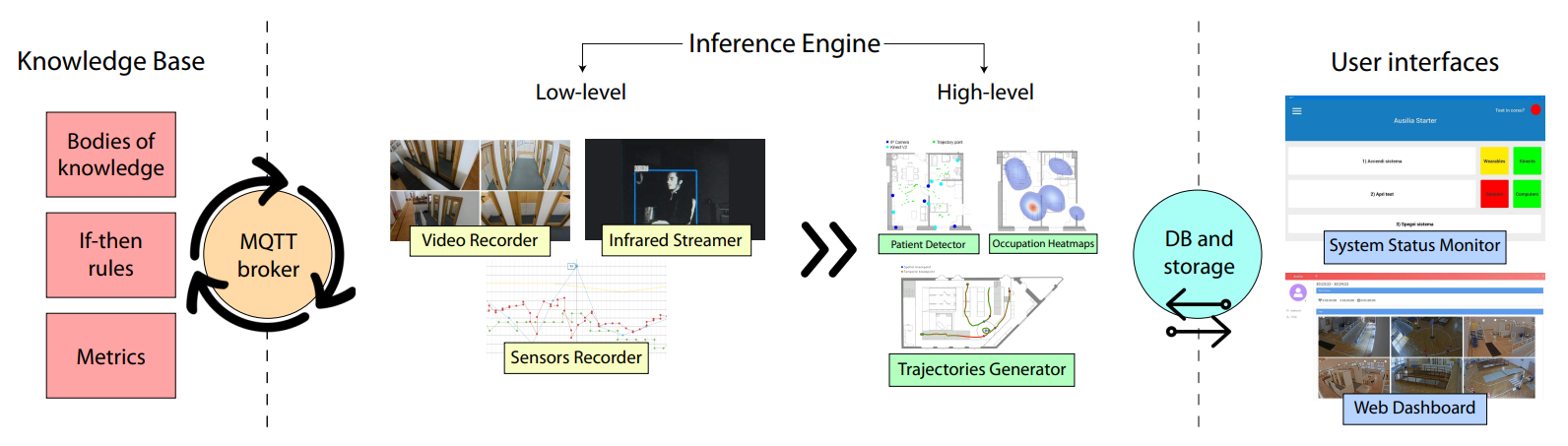
The recovery of motion abilities after a physical or neurological trauma is a long and winding road that is usually supported by medical staff. In particular, occupational therapists (OTs) play a fundamental role in assessing the performances of patients in daily life tasks and suggesting better practices and aids. The goal of OTs is to promote the patients abilities, fostering their independence with the minimum needed supervision. To this purpose, the possibility of remotely operating while being able to monitor the subject with a sufficient level of detail is highly desirable. The development of advanced tools for patient monitoring and supervision with limited intrusiveness is a scientific challenge that spans different technological areas: sensing, localisation, tracking, measurement, business intelligence. The final goal is to provide medical doctors with a set of meaningful metrics related to the patient s activity. Among them, occupation of living spaces, motion patterns, posture, as well as fine-grained motion-related parameters (e.g., grasping objects, performing elementary tasks of variable difficulty), can be of great help for the medical staff to assess the degree of independence of the user and to recommend suitable assisting devices, more appropriate organisation of living spaces, effective rehabilitation procedures. In this work, we describe a sophisticated setup that has been developed in strict cooperation with medical experts and researchers in both engineering and medicine, to create an augmented reality physical environment supporting occupational therapists and rehabilitation staff in evaluating their patients performance and therapy activities. The proposed system is fully automatic and the users detection and tracking is completely markerless and vision-based. It comprises a set of realistic highly-infrastructured living environments, including sensing and actuation devices of different types, which are thoroughly described in Tables 1 and 2 The collected data are analysed by an automated expert system to extract the requested information, which is then presented inside the user interface. The underlying technological complexity is hidden to both patients and the medical staff, to guarantee minimum intrusiveness for the former and maximum operational easiness for the latter. During and after the patients staying inside the living spaces, the medical personnel is enabled to access a large variety of data through a unified interface and is provided with a pre-filled version of the standard patient card, a document that is otherwise filled in by hand. This allows both reducing the time requested for a medical diagnosis and producing a more objective and measurable assessment. A fully operating setup of our system is currently deployed within the living lab AUSILIA (Pisoni et al. 2016).
Recommended citation: Garau, Nicola, et al. "A multimodal framework for the evaluation of patients weaknesses, supporting the design of customised AAL solutions." Expert Systems with Applications 202 (2022): 117172. https://www.sciencedirect.com/science/article/abs/pii/S0957417422005607
Published:

Published:

Project course, Department of Information Engineering and Computer Science, UniTN, 2021
Teaching assistant for the Project Course on Computer Graphics (2019-2021).
Undergraduate course, Department of Information Engineering and Computer Science, UniTN, 2021
Teaching assistant for the course of Comunicazioni Multimediali (2019-2021).
Postgraduate course, Department of Information Engineering and Computer Science, UniTN, 2022
Teaching assistant for the course of Computer Vision and Multimedia Analysis (2019-2022).
